Backing Up IBM Financial Services Workbench Data
To get started with backing up data for IBM Financial Services Workbench you need to first understand where data created and used by IBM Financial Services Workbench is stored. The following graphic provides a high level overview of the components of IBM Financial Services Workbench.
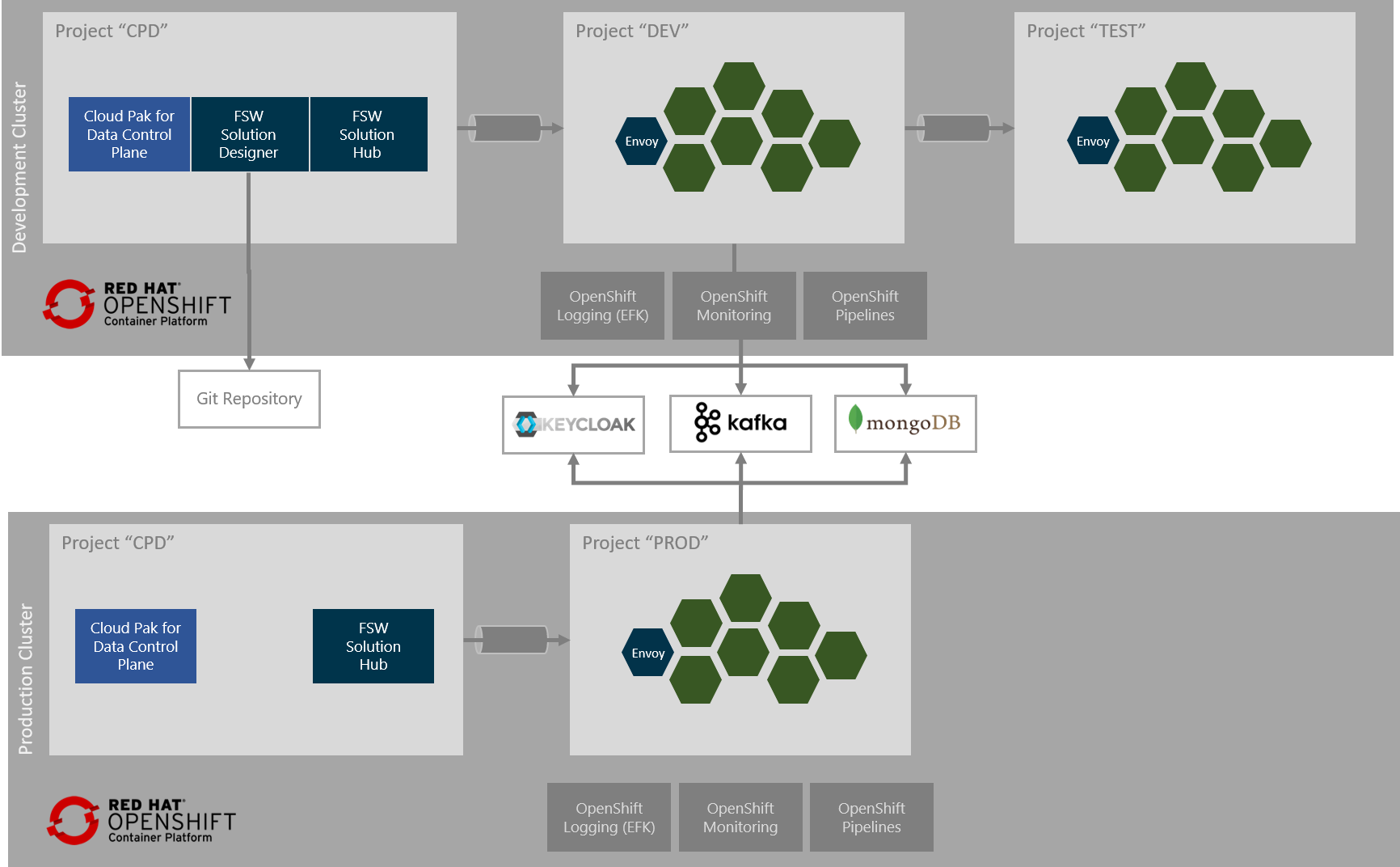
What you should immediately see is that various components making up IBM Financial Services Workbench are deployed to different OpenShift projects (e.g. "CPD", "DEV") and make use of different services that are not part of the product, i.e. mongoDB, kafka, a Git repository. The components can coarsely be grouped into two functional groups that can be thought of as components providing design-time and run-time functionality respectively that have different backup requirements. Let's look at them in turns.
Design Time Data
Domain experts and developers alike will use the components providing the design-time functionality (namely Solution Designer and Solution Hub) to create solutions to later provide functionality to your business. The data that is created is (domain) model data, implementation code and configuration. This data is stored in the following data stores.
Git Repository Server
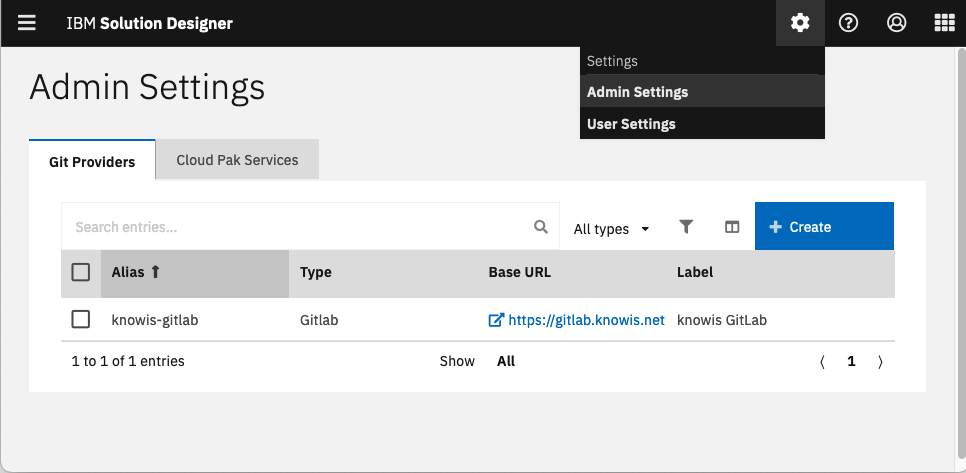
Model data and implementation code are stored in Git repositories hosted in a Git repository server like GitHub, GitLab or Atlassian Bitbucket. This is the source of truth for everything created with Solution Designer. IBM Financial Services Workbench doesn't provide an integrated service of this type and so backing up this data is the responsibility of the operator of the Git repository service. Since this is the most important data store for the design-time data a check of the backup strategy used for this or these (one can use multiple Git repository servers) services is advised. The precise ways on how to create these backups depend on the type and version of the Git repository server used and are therefore out of the scope of this document. You can find the currently configured Git repository services in Solution Designer under Administration (sprocket icon) -> Admin settings.
MongoDB for Solution Designer
While working in Solution Designer, a MongoDB database is used as a convenient workspace copy of the contents of a Git
repository. Any changes made to this database are written back when users of the Solution Designer or the (fss-cli for
developers creating implementation code) commit their changes. This database should also regularly be backed up if you
want to avoid losing changes made in between commits. This database can always be recreated from the contents of a Git
repository. This MongoDB service is also not provided by IBM Financial Services Workbench - instead an existing MongoDB instance that was
configured at installation time is used. Depending on the MongoDB service used (Cloud, cluster or on-prem) different
backup strategies are possible - see MongoDB Backup Methods.
See Pre-installation tasks
for how the used MongoDB instance is configured at install time. You can find the connection string of the MongoDB
instance used in your installation by reading the secret k5-designer-mongodb in the OpenShift project your Solution
Designer was deployed into:
oc -n <project of Solution Designer> get secret k5-designer-mongodb -o jsonpath='{.data.connectionString}'|base64 -d; echok5-designer-bundle.v1 in the namespace your Solution Designer is
installed to.oc -n <project of Solution Designer> get cm k5-designer-bundle.v1 -o jsonpath='{.data.release}'|base64 -d |gzip -cdSearch for a structure like the following:
k5-designer-backend:
mongoDb:
dbName: <name of the designer mongodb>
k5-Git-integration-controller:
mongoDb:
dbName: <name of the db used to store Git repository server configuration>S3 Object Storage
IBM Financial Services Workbench uses a built-in minio s3 object storage service to provide local marketplace functionality, i.e. sharing of solutions created in Solution Designer as templates or stencils to create new solutions amongst users of Solution Designer. To preserve these shared assets the contents of the minio service need to be backed up as well. You can explore the contents of this store by retrieving the credentials from the cluster:
# Access Key
oc -n <project of Solution Designer> get secret k5-s3-storage-credentials -o jsonpath='{.data.accesskey}'|base64 -d; echo
# Secret Key
oc -n <project of Solution Designer> get secret k5-s3-storage-credentials -o jsonpath='{.data.secretkey}'|base64 -d; echoIn order to use them you need to expose the minio service via creation of a route and then use any s3 client
i.e. minio client to list, retrieve and manipulate objects
there. This can be used for backup purposes - alternatively you can make sure the persistent volume requested by
PVC k5-s3-storage is backed up:
oc -n <project of Solution Designer> get pvc k5-s3-storageOne way to do this is described later.
Configuration Date
All configuration data is stored in kubernetes resources, i.e. ConfigMaps and Secrets. This is the data you create either initially at installation-time or when configuring various (runtime-)aspects via configuration management, either via API or via the configuration management UI in Solution Hub. To back up this data you need to back up all the kubernetes resources in the relevant namespaces. See "General OpenShift/kubernetes backup concepts" for a suggestion on how to achieve that.
Keycloak User Data
Authentication of users for Solution Designer is handled through Keycloak. Keycloak is not part of IBM Financial Services Workbench but is a pre-requisite for installation of the product. Depending on how you are providing Keycloak there might be different ways to back up user and Keycloak configuration data. See Keycloak Documentation for further information.
Run Time Data
Document Data - MongoDB
Solutions developed with Solution Designer are eventually deployed to provide business value. During execution of these
services, data will be created and stored. By default, this data is stored in a MongoDB. This data will in general be
the most critical data as it is the business data that your enterprise depends upon. Backing up this data is therefore
essential. IBM Financial Services Workbench doesn't bring this MongoDB instance but relies on you providing the connection data to a
MongoDB at installation time. You can find the configured connection data for the MongoDB by obtaining the value of
the k5-default-document-storage-service-binding secret in the OpenShift project that serves as the deployment target
for the solutions you develop (there can be more than one of those for different stages of development, testing, staging
and production)
oc -n <deployment project> get secret k5-default-document-storage-service-binding -o jsonpath='{.data.binding}'|base64 -d;echoEvent Data - Kafka
Asynchronous communication and messaging of solutions uses kafka as the message transport. Kafka is again a service that is not an integral part of IBM Financial Services Workbench but a service you need to (optionally) provide for the solutions you develop. The messages or events that are exchanged via kafka can also contain business data and depending on your use case might be as critical as the business data stored in MongoDB. Specific recommendations on how to back up kafka are beyond the scope of this document and the necessity to have regular backups of the data in kafka depends on your use case and whether you have activated kafka for your solutions or not. Backing up streaming data systems like kafka is non-trivial and recommended best practices vastly depend on your use case. There are many discussions in the community about this. See e.g. Comparing Kafka Backup Solutions
General OpenShift/kubernetes backup concepts
In addition to the business and design-time data, an installation of IBM Financial Services Workbench comprises of a number of kubernetes resources that are stored in the kubernetes etcd database. These resources contain a multitude of data relevant to your installation of the product and should also be considered when planning for a backup strategy. IBM recommends using the OADP Operator to help with backing up kubernetes resources. This operator helps to define backup configurations, backup locations and backup schedules that can back up resource data as well as persistent volume data to various (Cloud) object stores. If you run stateful services like MongoDB on your cluster and use cluster storage services supported by OADP and Velero - like OpenShift Container Storage , Portworx and similar products or the block-storage services of cloud providers like Amazon, Microsoft or Google, you can use OADP to create backups containing everything IBM Financial Services Workbench comprises of in a convenient way. Configuration and usage of these tools is dependent on your particular setup and storage technology and therefore out of scope of this document.
Conclusion
IBM Financial Services Workbench does not store business data but instead relies on storage services provided to the installation by the customer. Backing up data created through usage of the product is therefore highly dependent on the particular setup you have chosen. Hopefully this overview has given you some insight on what data is stored where and which are the most crucial data to consider for a backup strategy as well as providing some pointers to useful tools to assist you in these endeavors.